
分类,回归,聚类,降维
笔记摘录自bilibili网课数据挖掘
分类,回归,聚类,降维
分类 Classify
分类可以看作是机器学习中的有监督学习(supervised learning)
有监督学习:是指数据是有标记,可以量化的。针对日常生活中的某一个个体的相关数据,通过数据标签可以量化出一个专属于这个个体的特性类别,我们称这样的类别是标签(lable/target),是有监督学习的体现。
一个最经典的例子:性别预测问题,这是一个典型的分类问题。针对每一个人,我们可以根据他的外表数据,行为数据,来推断出这个人是男性还是女性。我们之所以可以随机的看一个人就可以立刻辨别出他(她)的性别,是因为一些性别的专属特征已经固化在我们脑海中。
有关人的特征数据(例如身高,体重,相关行为)我们用一个向量组来表示,组中元素被称为特征元素,例如[身高(height),体重(weight),相关行为(behavior)],我们称这是一个3维数据。
如何体现监督行为?在每一组特征元素向量数据$X$最后,会有一个特征标记$Y$,被称作标签(lable/target),是对当前向量组中数据元素的总结,如果没有这个特征标记则体现为无监督学习。
有监督学习的基本向量组的表达方式为
分类的向量组和数据矩阵
$$[data \mid label]$$
假设整个数据组中存在$N$个人,每个人具有$P$个特征元素,则我们可以得到一个$N \times P$ 数据矩阵,其中$N$为个数,$P$为特征数。数据元素统一用$X$来表示,label则用$Y$来表示。
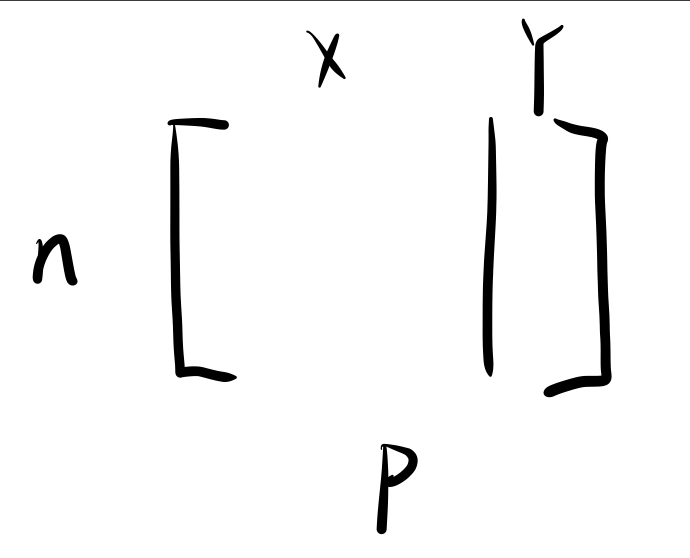
图片勘误:最下方角标应该是$P \mid Y$,而不是$P$,$P$只表示竖线左侧的数据元素而不表示标签。
分类的模型训练过程
首先我们通过已知的1特征数据矩阵(包括特征元素和target标签)来训练模型,今儿对没有label的全新的数据元素(dew data)向量组进行标记,得出label。并且尽可能保证推断出的label标记和真实情况的label保持一致。准确性(accuracy)越高,说明模型训练得越好。
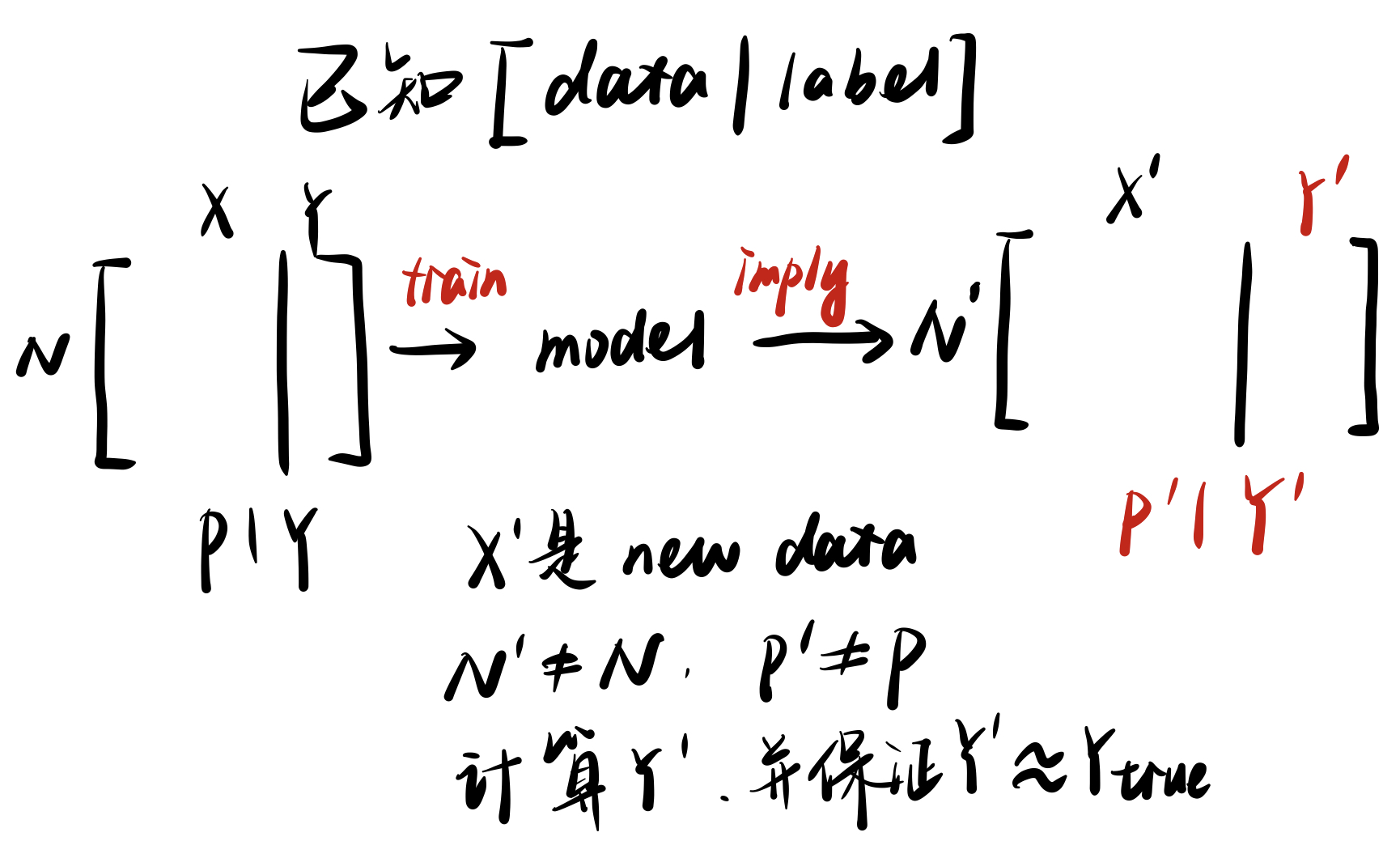
新模型中的数据维度可能与原数据不相同,虽然模型过程是数据矩阵的形式,但是本质上是对每一个数据元素向量组的推断,通过已有模型得出target label。
回归 Regression
回归是我们最早接触的一种数据化类类型,例如我们初中就接触过的线性关系:探寻身高与体重的关系等等。
分类和回归因为目标不同,所以导致最后的label也不是一致的。分类重在对以后数据进行模型训练,进而对新的没有进行分类的数据进行推断,得出新数据的label。而回归重在对原始数据的内在联系进行分析。对于给定的特性元素向量组和标签label,通过回归来找到内在关系。
基本回归变量类型
- 数值型变量 numerical data
- 类别型变量 categorical data
- 二分类变量 binary data
数值型变量和类别型变量的最明显区别:数值型变量可以进行比较(comparable),类别型变量不能比较(uncomparable)在类别型变量中讨论最多的就是二分类变量
$$Y = \alpha x_{1} + \beta x_{2} + … +\gamma x_{n}$$
其实就是我们常见的模型关系,上述公式表述的是数据型变量的关系,而类别型变量就是将具有某一特性类别集合的特征向量组聚合起来,找出共性关系。
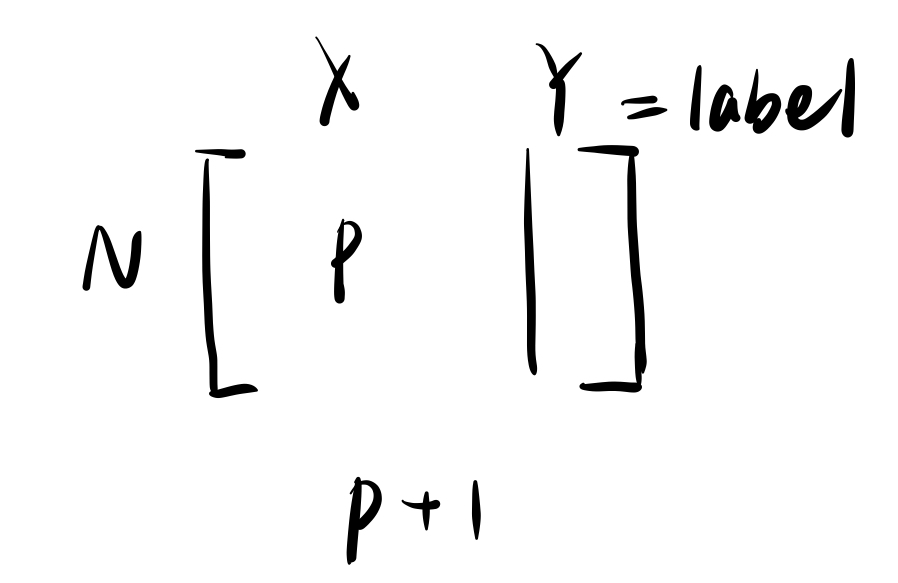
写成数据矩阵的形式如下图:
聚类 Clustering
聚类是无监督学习(unsupervised learning)的代表,即数据无标注(没有label)。
聚类是针对于数据本身进行的划分,相当于做了一个特征工程。其目的本质上就是为了让数据变得更“好看一点”,数据聚合可以让组内数据更加紧密,让组间数据差异尽可能更大。诸如聚类的无监督学习其实是作为有监督学习的辅助,让有监督学习可以更好地执行。
聚类模型训练过程
针对一个没有label的数据矩阵,对该矩阵进行标记,即使用一个已经进行过聚类的数据组来训练模型,然后让一组新的,没有进行聚类的数据进行聚类划分。得到一个一个的特征集群。
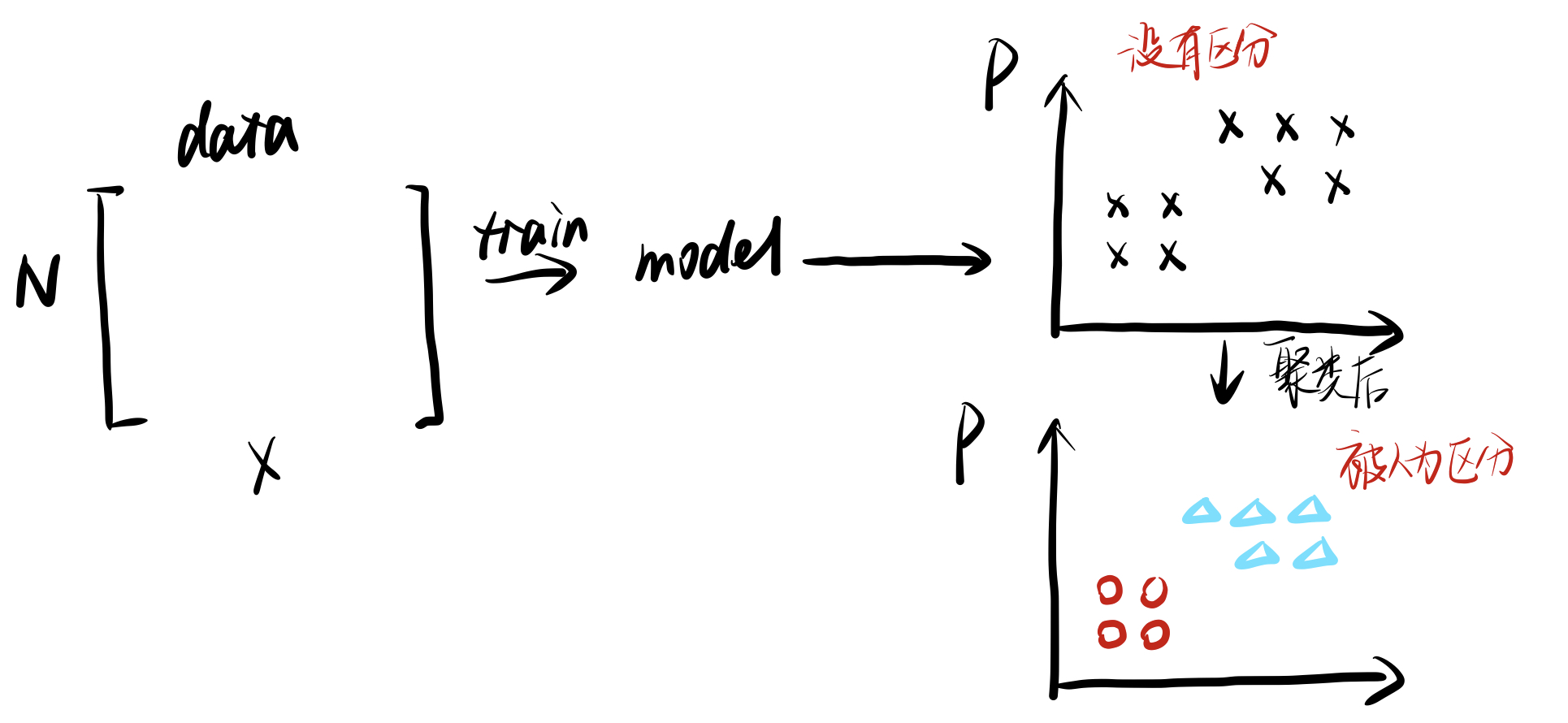
其中$X$为特征向量,$N$为组数,$P$为特征元素,可以很明显看出来聚类后特征元素被区分成不同的组(特征类群)。
降维 Dimension Reduction
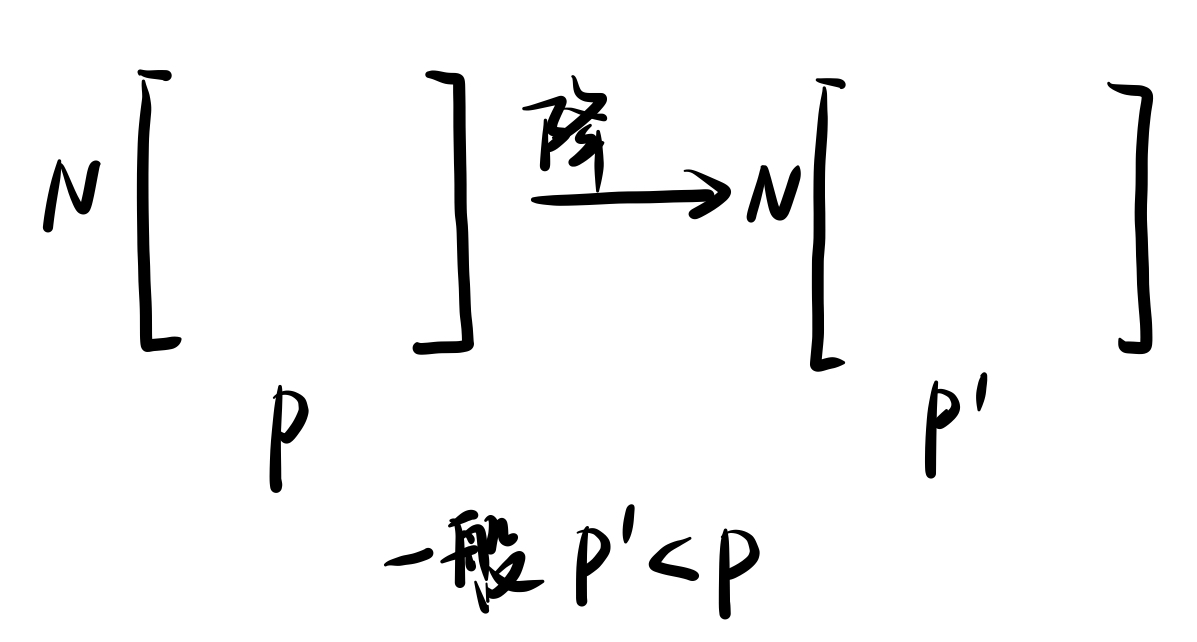
降维也是无监督学习的一种,通过减少冗余特征元素的方式实现对数据的优化,一般情况下,降维之后的特征元素维度要低于降维之前,即$P > P^{`}$
- 数据相关信息可能会丢失
- 降维可以减少数据噪声
- 降维可以对数据进行清洗,让脏数据变干净
高维度数据和低维度数据
- 高维数据 High-demensional Data
- 低维数据 Low-dimensional Data
如何判断一个数据矩阵是高维数据矩阵还是低维数据矩阵?
如果在一个数据矩阵中,如果$P > N$,则我们认为这个数据矩阵一般是高维度的,因为这样的数据矩阵在多元线性回归中并不能拟合出相关线性。
其实一般认为如果$N$约等于$P$也被算作高维度数据矩阵,具体要看模型效果,并不是绝对的。还有一种特殊情况,如果说在数据特征向量组中,有一组数据响亮可以通过另一组数据向量演化过来的。这样的数据被称为多重多样性,我们也认为这是高维度数据。
 微信
微信 支付宝
支付宝








